之前在做2019深圳杯的D题,要做电视广告和观众的匹配模型。那时候的一个想法是,把这些电视节目依据它们的类型来聚类, 从而达到分类效果,再针对分类后的电视节目给它们匹配广告,从而实现匹配模型。 虽然最后没有采用这个方法,但我也因此学了爬虫,也算有所得。
拆解任务
- 打开爱奇艺
- 输入搜索词,并点击搜索
- 点击搜索结果,提取类型的文本
- 把结果记入excel表格里
爬虫实现
打开网页
我用的是chrome,所以要下载与chrome版本相对应的Chromedriver。 当然也可以使用其他浏览器,下载对应的插件就好了。
代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.iqiyi.com/lib/m_215411214.html?src=search") # 用get打开网页
搜索
代码如下:
from selenium.webdriver.common.keys import Keys
from time import sleep
driver.find_element_by_xpath('//*[@id="j-header"]/div[5]/div/form/div/span[1]/input').send_keys(q) #输入搜索词q
sleep(1) #防止操作过快,避免被认为是非法访问
driver.find_element_by_xpath('//*[@id="j-header"]/div[5]/div/form/div/span[2]/input').send_keys(Keys.ENTER) #点击搜索
driver.switch_to_window(driver.window_handles[1]) #切换界面,从原页面切换到搜索结果的界面
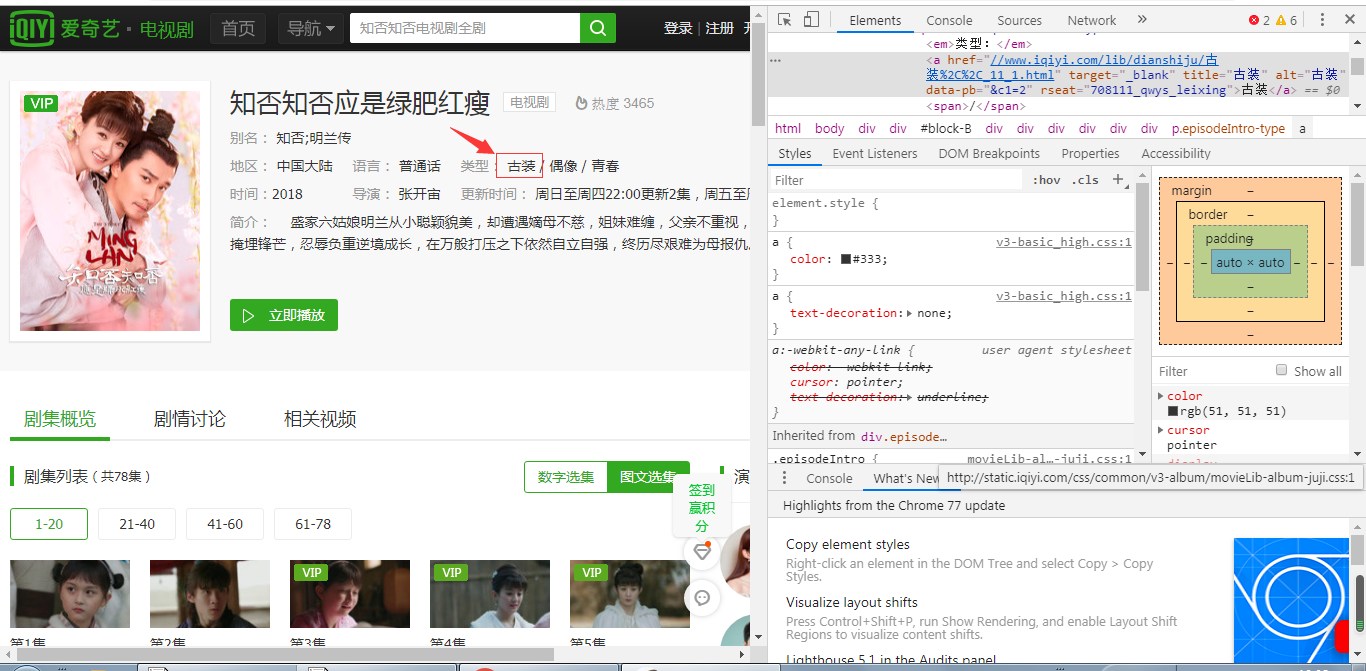
这里通过xpath来定位元素。要获取元素的xpath,只需右键,点击检查,依照下图找到该图标,点击,再去原页面上点击需要的元素。 当元素被选中后,在右边Element下面变蓝的框里右键,选择Copy->Copy Xpath,就可以了。

遇到的问题:若直接在爱奇艺首页进行搜索,不知道为什么向搜索键send keys是没有反应的。因此这里是打开爱奇艺的随便一个页面,再进行搜索
获取内容
import requests
from lxml import etree
driver.find_element_by_xpath('/html/body/div[1]/div[3]/div[1]/div/div[3]/div/ul/li[1]/div/h3/a').send_keys(Keys.ENTER)
driver.switch_to_window(driver.window_handles[2])
html = requests.get(driver.current_url) #获取该网址的html
driver.quit() #关闭网站
etree_html = etree.HTML(k.text) #k即html
content = etree_html.xpath('//*[@id="block-B"]/div/div/div[2]/div[2]/div[2]/div[3]/p[1]/a/text()') #获取内容
获取内容要在Xpath后面 加/text() 才能获得
选择元素时要注意,选的是类型下面的所有文字,而不是其中一个类型。
例://*[@id=”block-B”]/div/div/div[2]/div[2]/div[2]/div[3]/p[1]/a[1],这里对应的只是古装,而不是古装 / 偶像 / 青春, 所以重点是把a[1]改成a ,就能获取所有的类型。
完整代码
把需要搜索的节目名称都储存在excel,然后读入文件,提取数据,再进行搜索,最后将搜索结果写入excel里。
代码如下:
import requests
import xlwt
import xlrd
from xlutils.copy import copy
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
workbook = xlrd.open_workbook(r't.xls')
wb = copy(workbook)
sheet1 = workbook.sheet_by_index(0)
cols = sheet1.col_values(1) #读入excel
ws = wb.get_sheet(0)
def test(q):
driver = webdriver.Chrome()
driver.find_element_by_xpath('//*[@id="j-header"]/div[5]/div/form/div/span[1]/input').send_keys(q)
sleep(1)
driver.find_element_by_xpath('//*[@id="j-header"]/div[5]/div/form/div/span[2]/input').send_keys(Keys.ENTER)
driver.switch_to_window(driver.window_handles[1])
try: driver.find_element_by_xpath('/html/body/div[1]/div[3]/div[1]/div/div[3]/div/ul/li[1]/div/h3/a').send_keys(Keys.ENTER)
driver.switch_to_window(driver.window_handles[2])
html = requests.get(driver.current_url)
driver.quit()
except:
print("not found")
driver.quit()
return html
def get(k):
etree_html = etree.HTML(k.text)
genre = etree_html.xpath('//*[@id="oldNavCtrlElem"]/div/div/div[1]/div[2]/a/h2/text()')
content = etree_html.xpath('//*[@id="block-B"]/div/div/div[2]/div[2]/div[2]/div[3]/p[1]/a/text()')
content2 = etree_html.xpath('//*[@id="block-B"]/div/div/div/div[2]/div[2]/div[2]/div[3]/p[2]/a/text()')
content1 = etree_html.xpath('//*[@id="block-B"]/div/div/div[2]/div[2]/div[1]/div[3]/p/a/text()')
content3 = etree_html.xpath('//*[@id="block-BB"]/div/div/div[2]/div[2]/div[1]/div[2]/p/a/text()')
content4 = etree_html.xpath('//*[@id="block-BB"]/div/div/div[2]/div[2]/div[1]/div[3]/p[1]/a/text()')
content = genre+content+content1+content2+content3+content4
print(content)
return content
for i,j in enumerate(cols):
q = j
try:
k = test(q)
content = get(k)
for m,n in enumerate(content):
ws.write(i, m+2, n) #将搜索结果写入文件
wb.save('t.xls')
except:
print("not")
注意事项:
1.有时会发生电视节目类型为空,或者打开的网页不是资料页的情况。(因为这里默认打开搜索页面的第一条搜索结果。) 因此完整代码里面用了两个try···except ,一个是防止获取不到内容而报错,一个是防止写入文件时类型为空。
2.有些节目虽然类型为空,但是其实类型是有的,只是Xpath和别的不同。所以发生了较多的空错误后,需要去页面检查, 更新补上另外的Xpath。